
Business versus Technical Solutions
Last week I published an article here entitled “LandlordMax’s Most Challenging Bug” which received lots of comments both online and through personal emails (probably more people sent emails than commented). One thing that really struck me was the difference in thinking between people who run a business (from small ISV owners to managers) and technical people (developers, architects, etc.). Based on their background the solutions varied substantially. I’m not talking how to tackle the problem technically (btw there were some great tips and information being shared, thank you!), there was no doubt there was a lot of variation here, but I’m talking in terms of what types of solutions made economical sense.
What really struck me is that most developers completely ignored the cost to benefit side of the equation! I’m not saying that you should always base your decision on cost to benefits (I don’t want to acquire design debt for example), but sometimes this becomes a strong factor in the decision making. This is something that I use to lack, I always wanted to get in there and find the correct technical solution. The reality is that sometimes it’s not the right thing to do. This is a hard pill for technical people to swallow. I know it use to be for me. Not so much anymore being a lot more on the business side of things, but in the past it was a common issue.
Using my last article as a basis for this argument, let’s look at the cost to benefit of different types of solutions. Not actual solutions, but cost to benefits of the types of solutions. Rather than share my actual numbers, let’s just round realistic numbers to make the calculations, it’ll be much easier that way. So our first assumption is that allocating a developer to a task for 1 full day will cost $1000 in immediate salary. We should of course add in the costs of benefits, hardware, software, training, testing, etc., but for now let’s just say it’s $1000/day for a developer. Now remember this cost does not include any testing!
Ok, now I’ll assume that our fictional company makes $1 million in revenue a year, a simple round number. Assuming we have a unit price of $150 per unit, then this means we sell 6667 units per year.
Now before I proceed, let me backtrack a little. For those of you who are interested, you can read the full article here. However, just to get everyone up to speed, here’s the quick version. We found a bug in LandlordMax regarding how it reads certain types of JPG images. This bug is also present in many larger software application such as Internet Explorer and FireFox, so it’s not a simple solution. Also, images aren’t part of our core functionality. Don’t get me wrong, they’re a great feature, but we didn’t have them in the first 3 major versions. Now the problem is that we have two solutions, one that’s quicker to implement and one that isn’t. This problem only affects 0.05% of our total customers, and of those 90% will be satisfied with this solution. The other solution is complex, will take more than a week or two, and probably won’t fully work (IE and FireFox with very large resources still don’t have it full working). This solution will satisfy 90% of those customers too, possibly more.
Using these parameters, we can see there are two sides to this coin. Most technical people will want to fully solve the issue, to get it right. Yes the costs are high, but let’s do it right. The business side want’s to see what’s the cost to benefit. Now just a quick side step, you have to remember that you can’t always just look at the cost to benefit otherwise you’ll get so far into design debt that you’ll eventually kill your company. However, in this case, we’re not very likely to expand on this issue once it’s solved so it’s very unlikely that we’ll add any design debt no matter what solution we decide.
In any case, let’s look at the two solutions.
Solution 1:
An acceptable solution to the problem which will take about 1/2 a developer day, padded to 1 full day for safety. In this case, the cost is $1000. Now if we calculate it terms of cost to benefit, it means we’re paying $1000 for 0.05% of our 6667 customers, or 333 customers. On average, this means that we’re paying $3.33 to add this solution for these customers, of which 90% will be ok with the solution. The remainder would like a better solution but will probably live with it since this is only a small part of why their using the software, after all this is not the core functionality of the software. Also remember that these few people who are used to using this type of image mode also use to having this issue with a number of other major software applications. So it’s nothing new.
Solution 2:
We provide as best a technical solution as we can, knowing that we probably won’t be able to solve it fully as other software companies with budgets multiple orders of magnitude bigger larger than our total revenue can’t solve it. We’d be lucky to spend only a week, probably 2 weeks, and this might only reduce the number of people facing the issue by a percentage. But let’s be optimistic and say that we’ll solve it for 90% of the people who use this image mode.
Then in this case, we’ll spend 10 developer days, $10,000, to solve it. This means that it costs us $10,000 for our 333 customers. On average, this means we spend $30 per customer on this solution alone. This is now a significant percentage of the purchase price (20% of the total purchase price for fixing a small bug). But again, remember that it’s only for 90% of these 333, so we’re only really solving it for 300 people, bringing our per customer solution price to $33.33, or 22% of the total purchase price. We still have to deal with the remainder 10%, or 33 people. Assuming we use solution 1 for the remainder, this now brings up our price to $11,000, $10,000 for the initial solution and $1,000 for the remainder. Our total price per customer is now $33 for just this bug fix, or 22% of the total purchase price.
Which Solution is Right?
Which of these two solutions would you be more inclined to implement from a business side? What about from a technical side?
From a technical side, at least from my experience, we always want the perfect solution. But from a business side, it makes a lot more sence to go with solution 1. And don’t forget, solution 2 is probably a lot more costly than we estimated, it might take us a month, maybe two, or what if it’s a never ending series of issues? If the solution takes two months, which is not so hard to imagine once you see how Mozilla (FireFox) solved it (and that’s not even fully working), that brings our cost per customer to approximately $120 per customer. We’re now at 80% of the total purchase price for just one bug fix that’s not critical! Yes it’s only a portion of the customer, yes we could amortize it, yes we could calculate in the total lifetime purchases of the customer, and so on. But looking at the numbers when the first scenario is perfectly acceptable, I just can’t see how I can justify scenario 2.
As a developer, I can easily find ways to justify solution 2 such as design debt, etc. But from a business perspective solution 2 makes no sense!
UPDATE: Now add to solution 1 the fact that we now have an additional 9-10 developer days to add more features and benefits to the software. Let’s say we can increase our sales by 2% by instead allocating this same developer for the time difference to a new highly requested feature (maybe it’s only 1%, maybe it’s 10%, in any case, we’ll just use 2% since it’s easily feasible). If that’s the case, we can increase our sales of $1 million to $1,020,000, or by $20,000. Now not only have we paid for our bug fix, we’ve also paid for our developer and made a profit!
And the thing to remember here is that we’re not just helping 0.05% of the people (which we are), we’re also making 100% of the all our customers happier with a new feature (well maybe not 100%, but a much much larger percentage than 0.05%) that they wanted!
Permalink to this article Discussions (13)
LandlordMax's Most Challenging Bug
In the last little while we started to receive the same error/bug report coming through the Error Reporting functionality within LandlordMax. The error coming back was:
Error refreshing logo image javax.imageio.IIOException : Unsupported Image Type
Now this seemed weird to us, because we had all kinds of validations on which types of images to accept within LandlordMax. Before I proceed, to give you some context, LandlordMax has the ability to import pictures (jpg’s and gif’s only) into it’s database for 2 things. You can import an image for your logo/letterhead which will appear at the top of all your reports, which is great for the property management companies that purchase LandlordMax (about 50-65% of our customer base). The other area where you can add pictures is for your tenants, buildings, and units. This is a new feature that many people requested and that we added with version 2.12.
Getting back to this bug, we added all kinds of validation checks when you import images, such as the file extension (does it end with .gif, .jpg, .jpeg, etc.). We also added validations where it tries to first read the file, in case someone tried to manually change the file extension. And so on. Basically a lot of validation checks!

Initially we received some error reports such as the one listed above, and we found that we had missed a few potential validation checks, which we added with one of the patches (version 2.12a). That did significantly reduce the number of error reports, but they didn’t fully go away. Of course not everyone upgrades right away, but with time it seemed to dwindle down very significantly to just a few random ones. However, like I had just said, it didn’t completely go away which we don’t like to see.
Yesterday, we were finally fortunate enough to have someone also send us their email address (an optional parameter in the Error Reporting Dialog Window) along with the Error Report. This was great for us in that we finally had a repeatable test case for this very elusive bug that we couldn’t replicate, and that was extremely rare. We immediately contacted this customer and had her send us the image she used for the logo/letterhead as we tracked it down to a specific line in the code. We got the image, saved it, and added it to our test database. No problems, no errors, no issues! What? That didn’t make sense.
We then contacted her saying we couldn’t reproduce the error and we would be very appreciative if she could send us her database so that we could investigate it in detail. She obliged us and when we immediately tried it we got the exact error. It didn’t make any sense…
So the next step was to manually extract the image from her database into an image file and try that. I know she already sent us the image, but you never know. We extracted the image and opened it up with an image viewing tool without any issues. Very confusing… This image opens up in our image viewing software but not in LandlordMax.
So we dug deeper. Nothing. I personally spent several hours looking at this issue with no luck. So onto the internet and Google Search. After another hour or two, I found a weird bug report from Sun (Bug ID# 5100094). This was the key to the issue. It appears that the Java language doesn’t support JPG images that were saved in CMYK mode and threw this exact exception. Like most people, I know what a JPG image is, but I don’t know the details of how it’s encoded, nor do I really want to know. Now I was forced to find out more about this.
Without getting into too many technical details, it appears that JPG’s can be encoded from a number of modes, with RGB being the most common by far, or at least that’s my understanding. CMYK mode exist, but it’s not very commonly used.
Therefore I quickly checked the images, and low and behold, the image I had extracted from the database was encoded in CMYK! But what about the image she had sent me before? Well I did some further investigation, and to show you just how prevalent RGB mode is, the image she had sent me was in RGB mode. I don’t know if it’s the browser that converted the image or what, but when I did “Save image as…” it saved it in RGB mode. I did some further testing, and when I saved the image in CMYK mode, both browsers weren’t always happy with the image (depending on how exactly I saved it). That was very surprising to me. So it wasn’t only LandlordMax that had difficulties with this image mode sometimes, the major internet browsers also did!
As soon as I converted the image to RGB mode, everything went smoothly and with no issue. This was probably the most brutal bug I’ve ever encountered (omitting concurrency issues and such and just limiting it to straight bugs). It wasn’t an issue with the software, so it wasn’t possible to track down in the code. It was an issue with the image file and the programming language’s support of the image type. The error message wasn’t very indicative of the error as it usual is. And I also can’t blame the Java language either if both the major internet browsers had difficulties with this image mode.
So now what are the options for LandlordMax? This particular mode is not supported by the programming language. Do we look for a third party component and buy it? This is a very expensive solution, it costs a lot of money, not to mention the integration time (which is probably going to cost more than the component)? Will it have other bugs? Testing costs… For the percentage of users, I don’t think this is a viable solution.
Right now I’m personally leaning towards doing an extra validation and trying to invisibly render it from the file directly before accepting it. I’m leaning towards it, I’m not satisfied with it yet as it will have a lot of performance overhead, every new image will have to be rendered before being accepted… Imagine if you add 100 pictures for your building unit and each one has to be rendered. Rather than take a few seconds to a minute to import, it could now take 5-10 or more minutes easily. Is it worth it? Could I do a check after the fact, when trying to render it? That’s a possible solution also but it opens up a whole other can of worms…
The reality is that we don’t yet have a solution to this issue. We’re going to further investigate our options and definitely solve it for the next major upgrade, which is now expected to be out next month rather than this month. This is probably the most challenging bug I’ve encountered simply because it was absolutely unobvious what the issue was, there was no way to track it down in the code, and there is no real, or obvious, solution to it.
For those of you who don’t program, I hope this gives you an idea of the effort that goes into producing a software like LandlordMax Property Management Software. And although this is probably the most challenging bug I’ve ever encountered, it’s also one of the most interesting because of its difficulty!
Permalink to this article Discussions (30)
Should You Use a Code Profiler?
If you’re a software developers, absolutely!!! No doubt about it!
Before I go on, let me just take a step back to explain what a code profiler is to those that aren’t familiar with the term since a lot of you here also aren’t software developers. And surprisingly, a lot of software developers have no idea what a code profiler is!
A code profiler is a software application that helps you find performance bottlenecks, pin down memory leaks and resolve threading issues in your software application. So in other words, it’s a tool that helps you find where your own software needs the most improvement.
You would think that with today’s amazingly fast machines you wouldn’t need to worry so much about performance or memory (threading is something you always have to worry about). Yes, that’s partially true, but not always! For LandlordMax, as the database becomes progressively larger, so does the importance of running a code profiler. As some of you may have noticed, we’ve really been pushing performance enhancements recently (for example: here and here), and there’s a reason why. When we initially ran our tests, we ran them with fairly large databases, but we’d only test one section at a time. Lately we’ve been really pushing the envelop, creating databases that are larger than any of our customers will ever have, and we’ve noticed some performance issues with these massive databases, as well as some memory issues.
So then the question becomes, why not just optimize everything? Because that’s incredibly time consuming and very expensive. But more importantly, it’s often a waste of time and money. Most of the improvements you’ll do won’t make any noticeable difference. For example, if a screen refreshes in 10ms versus 20ms, no one will notice, it’s too fast to be perceptible, even if it’s a doubling in speed! However the cost of this improvement may be significant, hence driving up the cost of the software! No one wants this, and there’s no real benefit to anyone in this case.
So what we’re left with is focusing on the main performance bottlenecks. How do we do this? Most people will think that you just look at code, it should be obvious. It’s not! Often where you think there’s a bottleneck is just plain wrong. This is one of the hardest things to do!
So where does this leave us? How do we do this? We could integrate within our application a bunch of timers, memory readouts, etc. that would continually post information out to the screen. I’d suggest against this because this is very time consuming, error prone, has the high probability of introducing unncessary bugs, and adds a lot of extra code to your application.
A better solution is to use a code profiling application. As LandlordMax is Java based, I can only talk about the Java code profiling application. There’s 4 main software solutions, all ranging greatly in price, how they tackle the problem of profiling, what features they offer, etc. They are: JProfiler, YourKit, OptimizeIt, and JProbe.
After some analysis, I narrowed our list of options down to either JProfiler or YourKit. I simply couldn’t justify the cost of OptimizeIt, and JProbe seemed still stuck back about a decade in terms of GUI (it just wasn’t friendly to work with at all).
I did personally contact both of the companies I was interested in evaluating (JProfiler and YourKit) and told them I was going to write a review here on FollowSteph.com about this topic. Both were enthusiastic about it, and each was willing to provide me with a free license to their application (thank you!) so that I could really try out their software packages. It’s great to see this kind of enthusiasm! It’s also great to see companies that really believe in their products!
That being said, after some experimenting, I’m going to say that I prefer JProfiler. YourKit was nice, but I found JProfiler’s interface much more intuitive, it provided me the information I needed in a very organized and obvious manner. This made finding the bottlenecks and memory issues much faster and easier! Therefore in my opinion, although both tools are powerful, but I recommend JProfiler as the better alternative.
To give you a few examples of some of the phenomenal improvements we got with LandlordMax, before we started using JProfiler, we ran a rent roll report that generated 521 pages of rents due (that’s a big database!) in less than 14 minutes. That seemed reasonable to us when you consider the size of the report. This same report now runs on my computer in 12 seconds!!! Yes you read that right, in 12 seconds! When we ran it with JProfiler, the performance bottleneck jumped right out at us. It was not at all where we thought it was, we had been focusing on the wrong area of code. Had we not used JProfiler for this, we could have spent many more hours, possibly days, trying to improve the performance and it would have only been minor, maybe we would have shredded one minute from the total time, nothing like what we achieved.
Also, remember that the time cost to fix this was extremely small, once we saw it in the “CPU Views” section, it was a no-brainer. Solving it wasn’t obvious, but locating the source of the issue was! Much like locating the leak in a pipe can be brutal, but once you know where it is, solving it isn’t nearly as difficult. With JProfiler we were able to find it in seconds, with just one pass of the report.
Although I’ve been mostly mentioning performance bottlenecks, memory leaks (or extraneous usage) can and also does happen. While running JProfiler we also found that we used more memory than necessary in many places. We immediately saw that our “instance” count was extremely high for Vector Objects (a Java library object that stores a list of other objects). Why was our instance count so high? By quickly drilling down JProfiler’s Call Tree, we immediately noticed the issue.
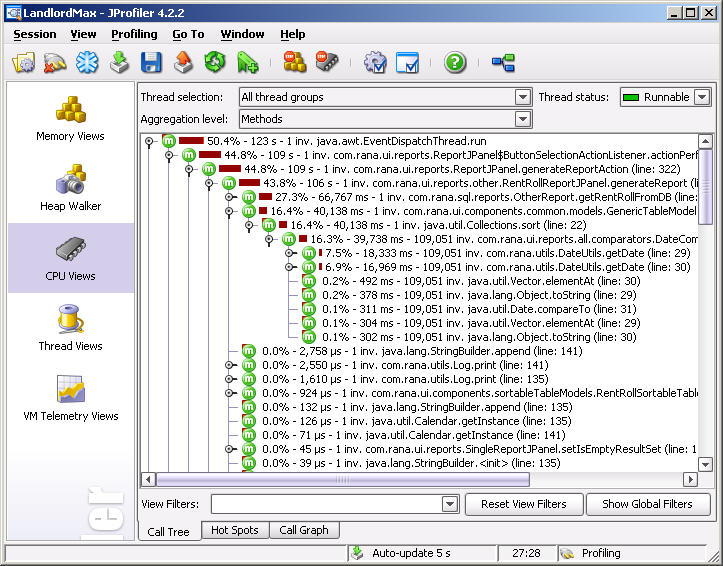
What was happening is that for each Model Object we created (a chunk of programming code that represents either a real world object or a concept), we were pre-creating several empty Vectors (lists). I know that without a context this doesn’t make much sense, so let’s give it a context. So for example, when we created a new Building Object, we would pre-create an empty Vector (list) of units, of accounting entries, and every other item that might be in the tabbed panels. There’s nothing wrong with that. When we were in the list view (where you would only see the list of buildings without the details), we only populated the basic building information so that it could be drawn in the table, not the full data (the list of accounting entries, etc.). We didn’t populate these lists (accounting entries, etc.) for every building because you might never view most of the buildings every time. Why take the performance and memory hit to pre-populate all the data if you probably will only use a small portion of it. Therefore we’d only populate the lists (accounting entries, etc.) for a building when that building was selected. This way, only when we actually look at the details of a building do we put information in our Vector Objects (accounting entries, etc.).
So how can there be a memory leak here? Well there isn’t one really. But what happens is that when we created a new Building we’d also create several empty lists (accounting entries, etc.) by creating a new Vector Object with no items in it. Still don’t see where the memory leak is? To be honest in retrospect it’s really obvious, but at the time I hadn’t really thought of it. The memory leak is that each of those empty Vectors Objects take memory. Each Vector Object has to be created (instantiated and allocated). Although the list contains nothing, the Vector Object does take up space. If you only have a few hundred buildings, it’s almost unoticeable. But now imagine that you have thousands of buildings, each with about a dozen empty Vector Objects! What about if you run a rent roll report like the one above with 521 pages of Objects each containing a dozen or so empty Vector Objects (lists)!
I wasn’t even looking for a memory issue in this area of the code, but by just running JProfiler while performing some random tasks quickly brought this to my attention. Of course, I had I run LandlordMax with a database of only a few hundred buildings I probably wouldn’t have noticed anything. You see in Object Oriented Languages such as Java, almost everything is an Object, there’s lots of Objects. Each Screen is an Object itself composed of many other Objects (Button Objects, Label Objects, etc.). There are Objects everywhere. But in this case because the database was much larger, the Object count quickly got out of proportion and it became very obvious when looking at the metrics within JProfiler.
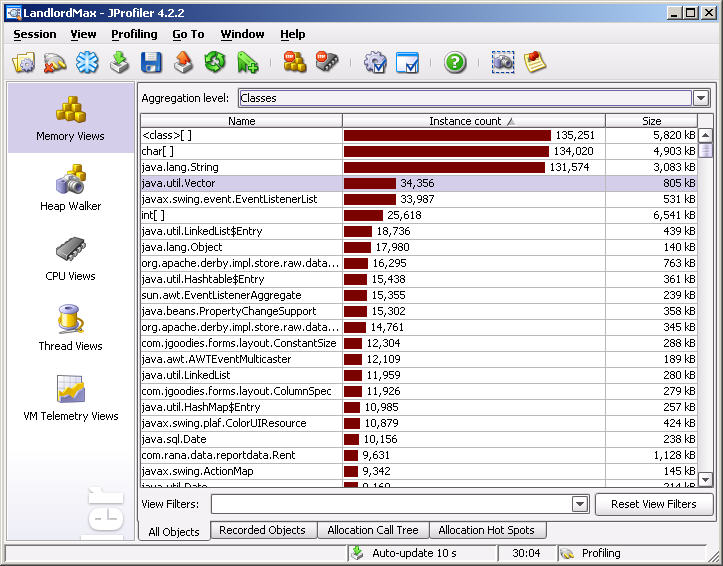
So to fix this little issue, all we had to do is go from created empty Vectors (lists) to using lazy instantiation. What that means is that we don’t even create an empty Vector, all we basically do is say this is where the list will go in memory. We don’t actually put a list there, not even an empty one. In Java, we assign it the value of “null”. Without getting too technical, variables generally point to the Object in memory, they don’t store the actual Object (pass by reference rather than pass by value). So when we put “null”, we don’t need to worry about allocating that Vector Object right now, we can deal with it later if need be (or never if we don’t need to). if you want more details this article explains it in a lot more detail. Anyways, doing this greatly reduced the amount of memory we used everywhere. Had I not run a code profiler like JProfiler, I don’t think I would have noticed this. It’s not a show stopper, but the less memory your software uses the better, and generally the faster it is. It didn’t need to create and destroy all these empty Vector object instances for nothing.
Another great benefit we quickly got with JProfiler is that it showed us our data entry screens needed some performance boosts. Up until now, we generally focused on the list views, as those are the ones that contain the biggest amount of data. But JProfiler quickly brought to our attention that the combo boxes can be performance issues. For example, when I go to create a new accounting entry where the database contains over 2000 tenants, 2000 buildings, 2000 vendors, etc., each of these respective combo boxes need to be redrawn (in case any data updates were made). Each combo box requires a database call. Each combo box requires some Objects to be created and destroyed as they are updated. This quickly added up and became really apparent with a large database just by looking at the screens within JProfiler.
Because of this, we’ve now added some caching to LandlordMax which will be available in the next major release. As I mentioned earlier in this article, we could have cached everything, but because of JProfiler we focused on only caching the combo boxes that had performance and memory bottlenecks (which ended up only being 5 combo boxes). Talk about a time saver! I can’t imagine having created caching for everything! By analyzing the metrics, we found that 99% of the performance bottlenecks could be attributed to only 5 combo boxes, which is a lot less than hundreds of potential combo boxes, labels, prefilled data entry fields, etc.
As a quick side note, those of you who aren’t familiar, caching is a way of storing information in memory so that it doesn’t have to be retrieved from the database each time (and also a way of re-using the same Object instances rather than re-creating new ones each time). Because of this, if no changes occur between screens (for example no tenants are added, removed, or modified), the combo box is virtually instantaneously drawn and consumes no extra memory. If a change do occur (a tenant’s name is modified, etc.), we now just update the cached tenant list so that it still doesn’t require a full database call or the creation of new objects. If you have thousands of tenants, buildings, units, vendors, etc., this can quickly add up.
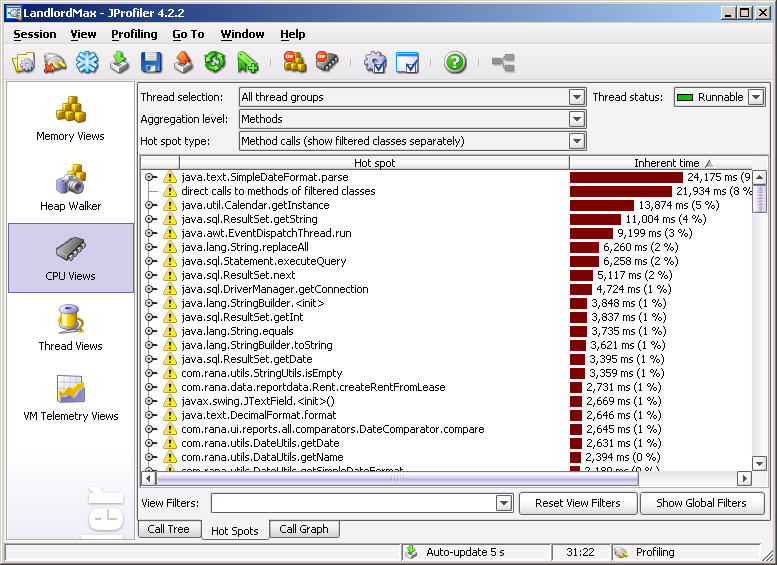
Before I finish this article, I just wanted to point out JProfiler’s “Hot Spot” functionality which is available for memory and performance analysis. This is basically a feature within the software that tries to actively point out to you where the bottlenecks are, so that you don’t have to look any further. Think of it as a summary of where you should look next, where you should look to enhance your software. It’s a nice little feature. Now that I think about it, it’s almost like it generates a “to do” list for you on where you should focus your time and money to enhance performance.
So have I convinced you that you (at least you software developers and software company owners) that you should run a code profiler for your software application if you haven’t already done so? I hope so! These were only some of the highlights we got from using JProfiler, there were others (I didn’t even mention any of it’s thread analyzing capabilities!). As you can tell, I really benefited from using JProfiler, so I definitely recommend them, especially if you’re coding in Java. The value in terms of time, cost, and benefits is definitely worth it!
Permalink to this article Discussions (10)
How Much Effort is There in Each Software Update?
Software releases generally come in two flavors, updates and upgrades. Updates are small changes where the version number barely changes and mostly consists of bug fixes, enhancements (perhaps performance), and possibly some new small features. Upgrades are generally considered major releases and often the first number of the version changes. These include major enhancements and lots of new features. Now everyone knows a lot of work goes into major new upgrades, there’s no doubt when you look at the list of new features. But what about updates? How much effort is involved in releasing updates? More than most people realize!
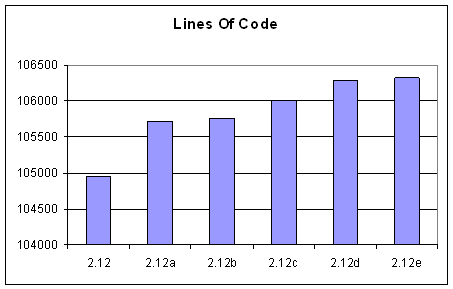
I just took a look at all the updates we released for LandlordMax Property Management Software version 2.12, which is now at version 2.12e, and it was quite lengthy as you can clearly see from this list of new features and fixes for each update. What’s the best metric to show how much effort was involved? That’s very debatable. One could argue LOC (Lines of Code) but that’s very skewed.
To give you a quick idea of why that’s skewed, let’s take a look at some of the huge performance enhancements we did for version 2.12c. Between version 2.12b and version 2.12c, as you can see from the graph below, we added about 250 new lines of code. Very few. But if you look at the effort, it took us many man hours to accomplish, probably more than all the other updates combined! So why so few lines of code? Because we removed as much if not more software code than we added. On top of this, a lot of the time we made modifications to existing code (for example optimizing the database queries), where we didn’t add or remove any code but just changed it. Version 2.12c was by far the update that required the most effort but this isn’t accurately reflected in the lines of code…
I can already see the next question, what about just measuring the total amount of time taken to implement each new update rather than using lines of code as a metric? That would be great except that we don’t really keep track here at LandlordMax of what we do in that kind of detail. I don’t know myself if I’ve spent two hours on this, then three hours on that. I know the total amount of time I spend working on LandlordMax, but I don’t know exactly on what. And to be honest, I don’t want to subject myself to this level of time tracking (even daily tracking) just to have metrics, it’s a waste of time and money. I’d rather spend that time adding more features to the software. I’m not billing a client, I’m trying to produce a software product, therefore the details of where the time is spent is not as important as building a quality product. With that being said, I do have a good idea of how much time each update took, a good guess-estimate. And I can tell you that version 2.12c was the largest by far.
In any case, I can only use the best metric I have in hand since I don’t have enough details to graph the time spent per update. Although this is not entirely accurate it’s the best I can do. That being said, it’s interesting to note that between the initial release of version 2.12 and the final release of version 2.12 (version 2.12e), we’ve added over 2000 lines of code. Assuming 40 lines per page, that’s 50 pages of new code. And remember, that’s not counting how much code has been modified, how much code has been replaced, etc.
So to answer the original question, how much effort is there in each software update? A lot! Based on the previous releases using only the lines of code as a metric, I can assure you that if we based it on time it would be a much larger percentage, we’ve added 10% as much code as a brand new full version upgrade release to the updates!
Permalink to this article Discussions (7)
LandlordMax Size and Complexity
There are many ways to measure the size and complexity of a software package, and all of them have their pros and cons. Although not entirely accurate, lines of code is one such standard metric, it allows you to see how large the program is growing. For those of you not familiar with lines of code, this is the count of the total lines of written computer language in a software application.
Of course I understand it’s not accurate, every developer writes code differently. For example one person could write a piece of code in 10 lines and another the same piece of code in 100 lines. Maybe one developer’s code is brutal to read and the other easy. Another’s is convoluted, overly complex, or is overly written because of bad architecture (or vice versa). For you non-developers, think of it this way, how many lines does it take you to tell a story? For Tolstoy (War and Peace anyone?), probably a lot. For another writer maybe it only takes a small fraction, a few pages.
In any case, it’s a good enough metric for us because we really push high quality code that is succinct, maintainable, and standard (for lack of better term). We prefer to refactor when the architecture is no longer sufficient. We don’t like to leave loose ends or to keep a larger code base (the code base is the total amount of programming code to make LandlordMax possible).
That being said, here’s LandlordMax’s lines of code growth curve over the last 4 major releases (omitting the minor updates) :
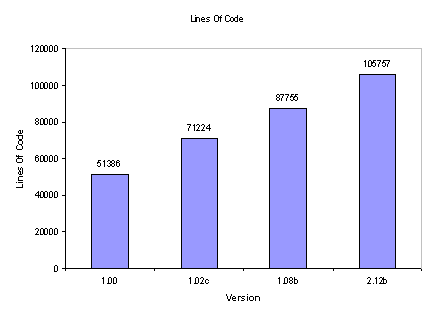
I have to admit that I myself was quite surprised at the “linearnous” of the graph (how straight it is). I suspected it was going to be much less linear, with “jumps”. But it makes sense if you think about, as we release each new version the code base gets more and more complex (there’s simply just more code) so it takes a little longer to build up on it. This is especially true when we need to make architectural refactorings that result in significant code changes with little or no additional lines of code added (sometimes the lines of code even get reduced). We had at least two of these significant architectural changes that I can quickly think of in the last major release: we changed the database engine and implemented table column sorting throughout.
Anyways, it’s just interesting to see how much LandlordMax has grown over time. The total lines of code may seem small for some developers/projects, but I think that’s because we spend a fairly larger amount of time on the architectural aspects of the software. I’d rather spend X amount of time now so that we save a larger amount of time adding new features today and tomorrow. Otherwise you can quickly and easily get caught always writing quick fixes and patches for one more feature after another until the system becomes completely unmaintainable. Not to mention that adding each new feature in the interim in such a system becomes exponentially more expensive!
If you’re interested in measuring your projects lines of code and you use cvs for your source code repository, there’s a great open source framework called Cvsplot which can produce some amazingly detailed graphs and text data file reports.
Permalink to this article Discussions (2)
The Database Engine Used by LandlordMax Will Now Come Bundled in the Java Language
It’s just come out recently that the next Java version (Mustang) will include Derby as part of the language itself, calling it “Java DB“. Yes, you read me right, it will be part of the actual programming language! Apparently the Java committee is so impressed with Derby that they are going to integrate it into the language itself and therefore support it. As far as I can tell, the main development effort will continue to be done by the Apache Derby Group, but it will then be repackaged as “Java DB” into the Java language.
This is great news! It definitely validates our choice of using Apache Derby as the database engine for LandlordMax. It means that Derby will continue to received substantial development efforts as it’s now going to be part of the actual Java language. If you think about, it also means that Derby has to be a pretty good database engine to become part of the language…
How will this affect the continuing development of LandlordMax? Although I can’t say for certain, I suspect that this was a great stroke of luck for LandlordMax! It can only positively affect the functionality and quality of our embedded database engine (thereby making LandlordMax an even better product).
It’s great to get such a positive boost of good luck out of nowhere once in a while!
Permalink to this article Discussions (0)
| « PREVIOUS PAGE |

